People Make Better Edits: Measuring the Efficacy of LLM-Generated Counterfactually Augmented Data for Harmful Language Detection
Abstract
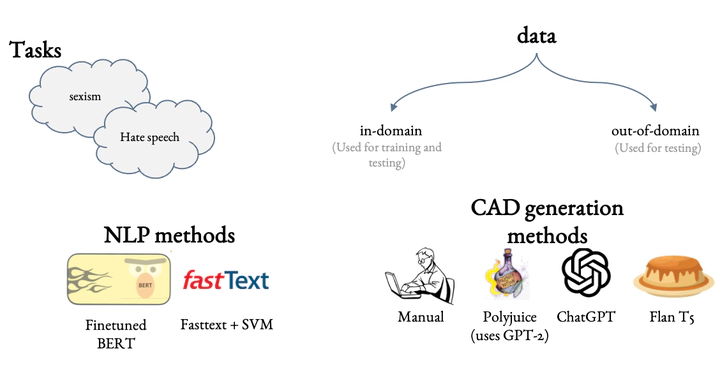
NLP models are used in a variety of critical social computing tasks, such as detecting sexist, racist, or otherwise hateful content. Therefore, it is imperative that these models are robust to spurious features. Past work has attempted to tackle such spurious features using training data augmentation, including Counterfactually Augmented Data (CADs). CADs introduce minimal changes to existing training data points and flip their labels; training on them may reduce model dependency on spurious features. However, manually generating CADs can be time-consuming and expensive. Hence in this work, we assess if this task can be automated using generative NLP models. We automatically generate CADs using Polyjuice, ChatGPT, and Flan-T5, and evaluate their usefulness in improving model robustness compared to manually-generated CADs. By testing both model performance on multiple out-of-domain test sets and individual data point efficacy, our results show that while manual CADs are still the most effective, CADs generated by ChatGPT come a close second. One key reason for the lower performance of automated methods is that the changes they introduce are often insufficient to flip the original label.
Dennis Assenmacher
PostDoc
My research interests include distributed robotics, mobile computing and programmable matter.